
How To Build A Llama 2 Chatbot
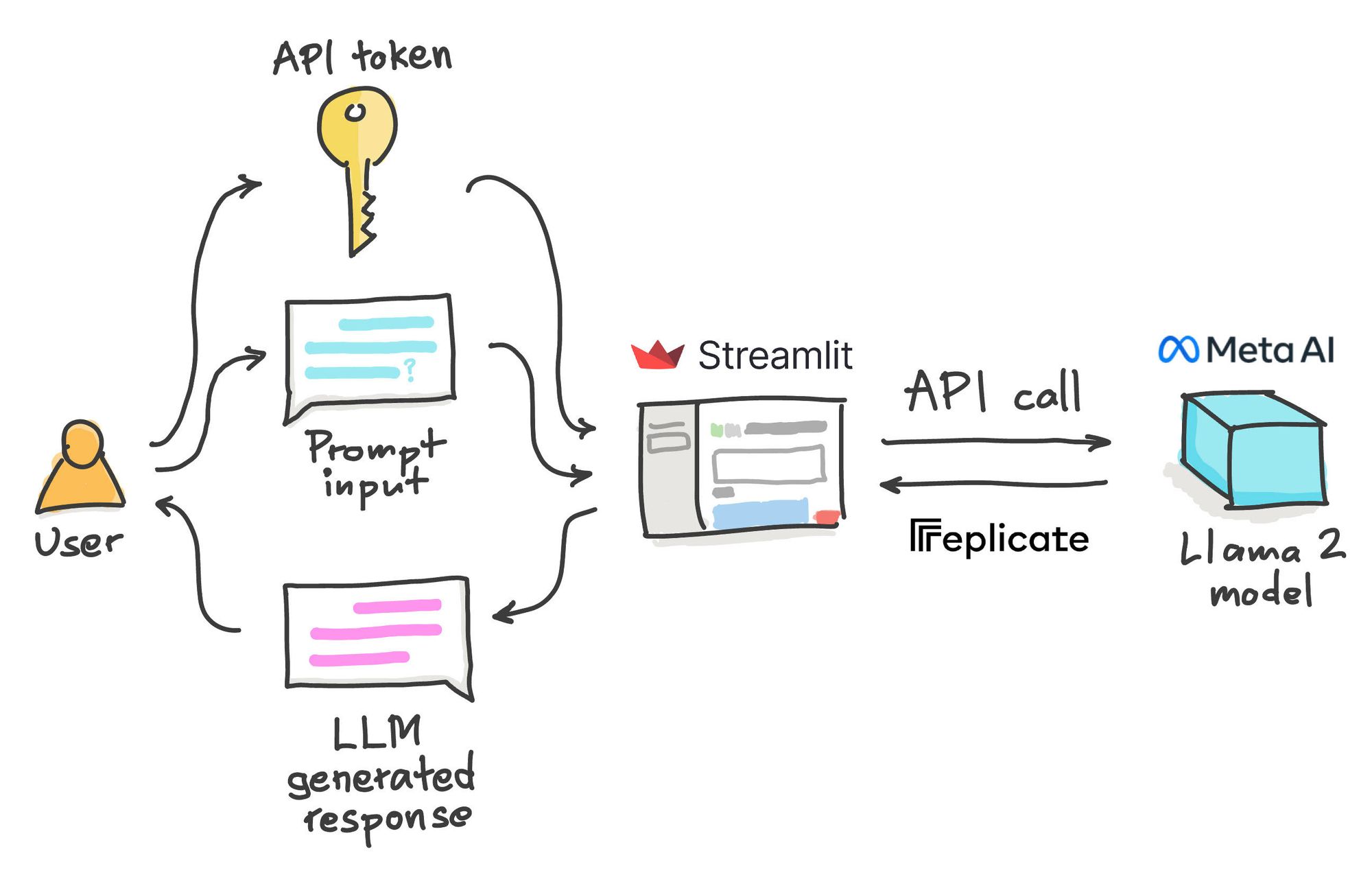
In this post well build a Llama 2 chatbot in Python using Streamlit for the frontend while the LLM backend is handled through API calls. Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or even name your pets. In this tutorial well walk through building a LLaMA-2 chatbot completely from scratch. Llama 2 was pretrained on publicly available online data sources The fine-tuned model Llama Chat leverages publicly available instruction. Across a wide range of helpfulness and safety benchmarks the Llama 2-Chat models perform better than most open models and achieve..
LLaMA-65B and 70B performs optimally when paired with a GPU that has a minimum of 40GB VRAM. More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x 4090 2x 24GB see here. Below are the Llama-2 hardware requirements for 4-bit quantization If the 7B Llama-2-13B-German-Assistant-v4-GPTQ model is what youre after. Using llamacpp llama-2-13b-chatggmlv3q4_0bin llama-2-13b-chatggmlv3q8_0bin and llama-2-70b-chatggmlv3q4_0bin from TheBloke MacBook Pro 6-Core Intel Core i7. 1 Backround I would like to run a 70B LLama 2 instance locally not train just run Quantized to 4 bits this is roughly 35GB on HF its actually as..

Llama 2 Revolutionizing Chatbots With Meta Ai
AWQ model s for GPU inference GPTQ models for GPU inference with multiple quantisation parameter options 2 3 4 5 6 and 8-bit GGUF models for CPUGPU inference. The size of Llama 2 70B fp16 is around 130GB so no you cant run Llama 2 70B fp16 with 2 x 24GB You need 2 x 80GB GPU or 4 x 48GB GPU or 6 x 24GB GPU to run fp16. Token counts refer to pretraining data only All models are trained with a global batch-size of 4M tokens Bigger models - 70B -- use Grouped-Query Attention GQA for. The 7 billion parameter version of Llama 2 weighs 135 GB After 4-bit quantization with GPTQ its size drops to 36 GB ie 266 of its original size. If we quantize Llama 2 70B to 4-bit precision we still need 35 GB of memory 70 billion 05 bytes The model could fit into 2 consumer GPUs With GPTQ quantization we can further..
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Download a PDF of the paper titled LLaMAntino LLaMA 2 Models for Effective Text Generation in Italian Language by Pierpaolo Basile and 5 other authors. We release Code Llama a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models infilling capabilities support for large. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters..


Comments